Generated from notebooks/mutation_map.ipynb
Generate a mutation map
This inotebook shall give an simple introduction in how to produce mutation maps for all models that are enabled for variant effect prediction. Let's use the DeepSEA/variantEffects model.
Variant selection
In this example we will first run the variant effect prediction code that is described in detail in the variant_effect_prediction_simple.ipynb. We will use these effect scores to select variants with the strongest effects to then visualise one of those variants in a mutation map.
# First let's select and setup the model:
import kipoi
model_name = "DeepSEA/variantEffects"
#kipoi.pipeline.install_model_requirements(model_name)
# The input vcf path
vcf_path = "example_data/clinvar_donor_acceptor_chr22.vcf"
# The output vcf path, based on the input file name
out_vcf_fpath = vcf_path[:-4] + "%s.vcf"%model_name.replace("/", "_")
# The datalaoder keyword arguments
dataloader_arguments = {"fasta_file": "example_data/hg19_chr22.fa"}
# Now actually run the effect prediction using the logit difference:
import kipoi_veff.snv_predict as sp
sp.score_variants(model = model_name,
dl_args = dataloader_arguments,
scores = ["logit"],
input_vcf = vcf_path,
output_vcf = out_vcf_fpath)
100%|██████████| 14/14 [00:34<00:00, 2.43s/it]
Just like in the variant_effect_prediction_simple.ipynb we will now load the results from the generated VCF into a dataframe for easy data access:
from kipoi_veff.parsers import KipoiVCFParser
vcf_reader = KipoiVCFParser("example_data/clinvar_donor_acceptor_chr22DeepSEA_variantEffects.vcf")
import pandas as pd
entries = [el for el in vcf_reader]
entries_df = pd.DataFrame(entries)
entries_df.index = entries_df["variant_id"]
Now we can select a subset of variants that score with the strongest score across the most model output tasks:
# select the 5 variants with the most universal strongest predicted effect in chr22
logit_cols = entries_df.columns.str.contains("LOGIT")
top5_vars = entries_df.loc[:,logit_cols].abs().idxmax().value_counts().head()
top5_vars
12342 305
16376 194
8374 127
22158 65
9970 54
dtype: int64
Now make a subset dataframe:
top5_df = entries_df.loc[entries_df["variant_id"].isin(top5_vars.index)]
top5_df
| variant_id | variant_chr | variant_pos | variant_ref | variant_alt | KV_DeepSEA/variantEffects_LOGIT_8988T_DNase_None_0 | KV_DeepSEA/variantEffects_LOGIT_AoSMC_DNase_None_1 | KV_DeepSEA/variantEffects_LOGIT_Chorion_DNase_None_2 | KV_DeepSEA/variantEffects_LOGIT_CLL_DNase_None_3 | KV_DeepSEA/variantEffects_LOGIT_Fibrobl_DNase_None_4 | ... | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H2AZ_None_910 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K27ac_None_911 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K27me3_None_912 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K36me3_None_913 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K4me1_None_914 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K4me2_None_915 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K4me3_None_916 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K79me2_None_917 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K9me3_None_918 | KV_DeepSEA/variantEffects_rID_unnamed_0_0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| variant_id | |||||||||||||||||||||
| 16376 | 16376 | chr22 | 29108009 | G | C | -2.560048 | -2.604959 | -1.476766 | -1.966083 | -1.286860 | ... | 0.068821 | 0.474027 | 0.227797 | 0.258411 | 0.544803 | 0.144552 | 0.175402 | 0.575531 | 0.055439 | chr22:29108009:G:['C'] |
| 22158 | 22158 | chr22 | 29121356 | C | G | 0.148644 | 2.256156 | 0.885380 | -0.016387 | 0.423442 | ... | 0.033477 | 0.043208 | -0.120319 | -0.324504 | 0.189594 | 0.147367 | -0.087590 | -0.388921 | -0.023764 | chr22:29121356:C:['G'] |
| 9970 | 9970 | chr22 | 36701970 | G | A | 0.504692 | 1.658696 | 1.032887 | -0.148108 | 0.914291 | ... | 0.321597 | 0.299887 | 0.003522 | -0.060838 | 0.473003 | 0.342598 | 0.247115 | -0.056063 | -0.063615 | chr22:36701970:G:['A'] |
| 8374 | 8374 | chr22 | 40750331 | A | G | 0.571587 | 0.248589 | 0.201321 | 1.890934 | 0.111852 | ... | 0.421956 | -0.020715 | -0.156171 | -0.151327 | 0.022475 | 0.192291 | 0.189058 | -0.144645 | -0.187582 | chr22:40750331:A:['G'] |
| 12342 | 12342 | chr22 | 50964903 | C | G | -1.935331 | -2.190516 | -1.468465 | -1.936842 | -1.670801 | ... | 0.236538 | 0.432350 | 0.886636 | 0.113601 | 0.007765 | -0.198594 | -0.245576 | 0.767322 | -0.188115 | chr22:50964903:C:['G'] |
5 rows × 925 columns
Based on that selection let's now generate an input VCF file that can then be used for mutation map calculation:
query_vcf = "example_data/clinvar_donor_acceptor_chr22_5vars.vcf"
variant_order = []
# now subset the VCF:
with open(query_vcf, "w") as ofh:
with open(vcf_path, "r") as ifh:
for l in ifh:
els = l.split(" ")
if l.startswith("#"):
ofh.write(l)
elif els[2] in top5_vars.index.tolist():
variant_order.append(els[2])
ofh.write(l)
! cat $query_vcf
##fileformat=VCFv4.0
##FILTER=<ID=PASS,Description="All filters passed">
##contig=<ID=chr1,length=249250621>
##contig=<ID=chr2,length=243199373>
##contig=<ID=chr3,length=198022430>
##contig=<ID=chr4,length=191154276>
##contig=<ID=chr5,length=180915260>
##contig=<ID=chr6,length=171115067>
##contig=<ID=chr7,length=159138663>
##contig=<ID=chr8,length=146364022>
##contig=<ID=chr9,length=141213431>
##contig=<ID=chr10,length=135534747>
##contig=<ID=chr11,length=135006516>
##contig=<ID=chr12,length=133851895>
##contig=<ID=chr13,length=115169878>
##contig=<ID=chr14,length=107349540>
##contig=<ID=chr15,length=102531392>
##contig=<ID=chr16,length=90354753>
##contig=<ID=chr17,length=81195210>
##contig=<ID=chr18,length=78077248>
##contig=<ID=chr19,length=59128983>
##contig=<ID=chr20,length=63025520>
##contig=<ID=chr21,length=48129895>
##contig=<ID=chr22,length=51304566>
##contig=<ID=chrX,length=155270560>
##contig=<ID=chrY,length=59373566>
##contig=<ID=chrMT,length=16569>
#CHROM POS ID REF ALT QUAL FILTER INFO
chr22 40750331 8374 A G . . .
chr22 36701970 9970 G A . . .
chr22 50964903 12342 C G . . .
chr22 29108009 16376 G C . . .
chr22 29121356 22158 C G . . .
Now we also want the dataframe to have the same order as the VCF:
top5_df = top5_df.loc[variant_order, :]
top5_df
| variant_id | variant_chr | variant_pos | variant_ref | variant_alt | KV_DeepSEA/variantEffects_LOGIT_8988T_DNase_None_0 | KV_DeepSEA/variantEffects_LOGIT_AoSMC_DNase_None_1 | KV_DeepSEA/variantEffects_LOGIT_Chorion_DNase_None_2 | KV_DeepSEA/variantEffects_LOGIT_CLL_DNase_None_3 | KV_DeepSEA/variantEffects_LOGIT_Fibrobl_DNase_None_4 | ... | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H2AZ_None_910 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K27ac_None_911 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K27me3_None_912 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K36me3_None_913 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K4me1_None_914 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K4me2_None_915 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K4me3_None_916 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K79me2_None_917 | KV_DeepSEA/variantEffects_LOGIT_Osteoblasts_H3K9me3_None_918 | KV_DeepSEA/variantEffects_rID_unnamed_0_0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| variant_id | |||||||||||||||||||||
| 8374 | 8374 | chr22 | 40750331 | A | G | 0.571587 | 0.248589 | 0.201321 | 1.890934 | 0.111852 | ... | 0.421956 | -0.020715 | -0.156171 | -0.151327 | 0.022475 | 0.192291 | 0.189058 | -0.144645 | -0.187582 | chr22:40750331:A:['G'] |
| 9970 | 9970 | chr22 | 36701970 | G | A | 0.504692 | 1.658696 | 1.032887 | -0.148108 | 0.914291 | ... | 0.321597 | 0.299887 | 0.003522 | -0.060838 | 0.473003 | 0.342598 | 0.247115 | -0.056063 | -0.063615 | chr22:36701970:G:['A'] |
| 12342 | 12342 | chr22 | 50964903 | C | G | -1.935331 | -2.190516 | -1.468465 | -1.936842 | -1.670801 | ... | 0.236538 | 0.432350 | 0.886636 | 0.113601 | 0.007765 | -0.198594 | -0.245576 | 0.767322 | -0.188115 | chr22:50964903:C:['G'] |
| 16376 | 16376 | chr22 | 29108009 | G | C | -2.560048 | -2.604959 | -1.476766 | -1.966083 | -1.286860 | ... | 0.068821 | 0.474027 | 0.227797 | 0.258411 | 0.544803 | 0.144552 | 0.175402 | 0.575531 | 0.055439 | chr22:29108009:G:['C'] |
| 22158 | 22158 | chr22 | 29121356 | C | G | 0.148644 | 2.256156 | 0.885380 | -0.016387 | 0.423442 | ... | 0.033477 | 0.043208 | -0.120319 | -0.324504 | 0.189594 | 0.147367 | -0.087590 | -0.388921 | -0.023764 | chr22:29121356:C:['G'] |
5 rows × 925 columns
Calculating the mutation map
Now we are set to generate a mutation map based on a VCF containing variants of interest:
import kipoi
model_name = "DeepSEA/variantEffects"
#kipoi.pipeline.install_model_requirements(model_name)
from kipoi_veff import MutationMap
Set up the mutation map object with the necessary information such as the model and dataloader objects as well as the dataloader arguments to actually perform the calculation
model = kipoi.get_model(model_name)
dataloader = model.default_dataloader
dataloader_arguments = {"fasta_file": "example_data/hg19_chr22.fa"}
mm = MutationMap(model, dataloader, dataloader_args = dataloader_arguments)
Mutation maps can be generated based on a VCF file (mm.query_vcf), based on a bed file (mm.query_bed) or in the python API also based on a region (mm.query_region) that is passed by arguments. Here we will be using the mm.query_vcf method:
mmp = mm.query_vcf(query_vcf, scores = ["logit"])
The object returned by mm.query_* methods are MutationMapPlotter objects that can either be stored in a hdf5 file or be used for plotting using their plot_mutmap method.
The data in the MutationMapPlotter is stored hierarchically by:
- Line of the query input (file), which is an integer number. For bed files the index is for regions of length of the model input that overlapped the regions defined in the region definition bed file.
- The name of the model (DNA sequence) input with regard to which the effect predictions were calculated.
- The scoring function defined by the
scoreargument - The model output task for which the effect prediction was calculated
Therefore also for plotting one must select the dataset that should be plotted. Here we will select the fourth variant in the VCF (id: 16376) and the model task which had the strongest absolute predicted effect in our initial variant selection.
# Fourth variant in the VCF
sel_line = 3
# Select the model output being affected the most by this variant:
model_task = top5_df.loc[:,logit_cols].iloc[sel_line].abs().idxmax().split("_LOGIT_")[1]
model_task
'SK-N-SH_RA_CTCF_None_385'
mmp.plot_mutmap(sel_line, "seq", "logit", model_task)
<matplotlib.axes._subplots.AxesSubplot at 0x2b0856e433c8>
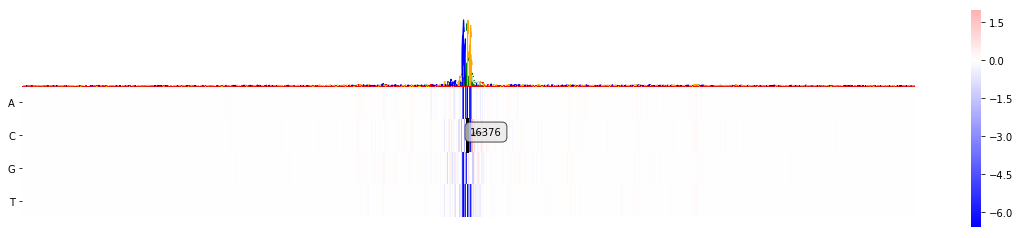
As we can see we can't see much. Everything is a bit squished, but the variant is already annotated with the ID that was given in the VCF file: 16376.
By default the full input sequence length is displayed, which is 1000bp for the DeepSEA model. In order to zoom in let's find the variant position and then zoom down to a 80bp window surrounding the variant:
var_pos = top5_df["variant_pos"].iloc[sel_line]
var_pos
29108009
In order to zoom in one can use the limit_region_genomic argument which accepts a tuple of two values - start and end of the genomic region (0-based) which should be selected for plotting.
mmp.plot_mutmap(sel_line, "seq", "logit", model_task, limit_region_genomic=(var_pos -40, var_pos+40))
<matplotlib.axes._subplots.AxesSubplot at 0x2b0857c1b198>
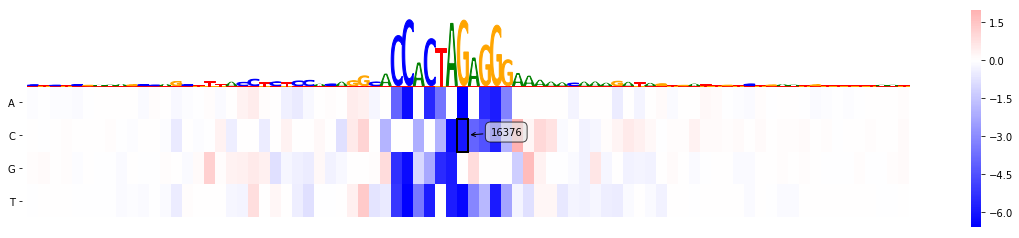
Now since we are looking at CTCF track one might suspect that the variant lies in a CTCF binding motif, but it is somewhat not 100% clear. Let's see whether a motif on the reverse strand is actually affected:
mmp.plot_mutmap(sel_line, "seq", "logit", model_task, limit_region_genomic=(var_pos -40, var_pos+40), rc_plot=True)
<matplotlib.axes._subplots.AxesSubplot at 0x2b085741f400>
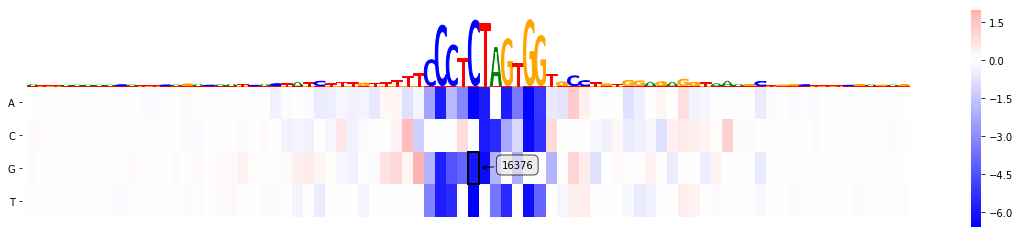
Add additional annotation (dbSNP)
Now that we know how to zoom and reverse-complement mutation maps let's also try and highlight further variants in the region. For that I have prepared a subset of variants of the dbSNP b151 GRCh37 All_20180423.vcf.gz in the proximity of the selected variant. We can use this VCF to highlight dbSNP variants in the region.
Let's first get the variant information into the right format:
import cyvcf2
vcf_obj = cyvcf2.VCF("example_data/dbsnp_chr22_29108009.vcf")
variants = {"chr":[], "pos":[], "id":[], "ref":[], "alt":[]}
for rec in vcf_obj:
# skip indels
if rec.is_indel:
continue
variants["chr"].append(rec.CHROM)
variants["pos"].append(rec.POS)
variants["id"].append(rec.ID)
variants["ref"].append(rec.REF)
variants["alt"].append(rec.ALT[0])
Now we can plug this dictionary into the plotting method and take a look at our annotated plot.
mmp.plot_mutmap(sel_line, "seq", "logit", model_task, limit_region_genomic=(var_pos -40, var_pos+40),
rc_plot=True, annotation_variants = variants)
<matplotlib.axes._subplots.AxesSubplot at 0x2b08574d6e10>
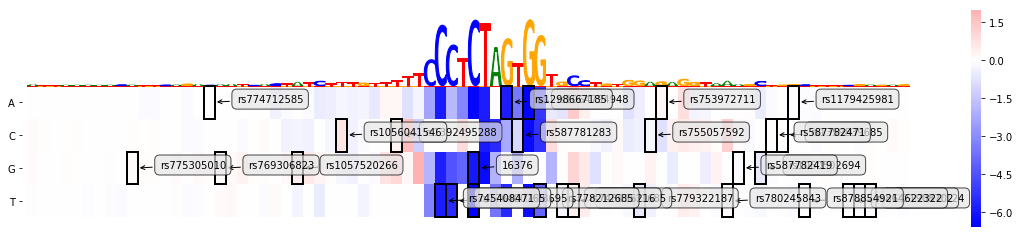
Arguably it's not the most beautiful plot as labels start overlapping, so let's remove them and let's also exclude out seed variant, in order to highlight the difference we might actually also want to change the colour of the variant boxes to red:
mmp.plot_mutmap(sel_line, "seq", "logit", model_task, limit_region_genomic=(var_pos -40, var_pos+40),
rc_plot=True, annotation_variants = variants, show_var_id=False,
ignore_stored_var_annotation=True,var_box_color="red", )
<matplotlib.axes._subplots.AxesSubplot at 0x2b086f892f28>
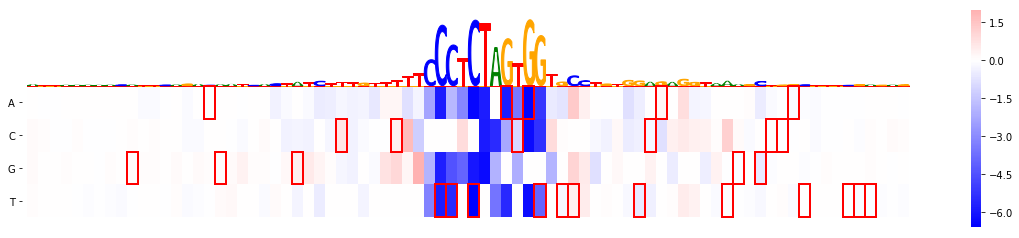
The CLI
Mutation maps can be calculated using the command line interface analogously to the way presented above for the python API. Let's therefore collect all the input and output file names:
import json
model_name = "DeepSEA/variantEffects"
dataloader_arguments_str = "'%s'"%json.dumps({"fasta_file": "example_data/hg19_chr22.fa"})
query_vcf = "example_data/clinvar_donor_acceptor_chr22_5vars.vcf"
output_file = "example_data/clinvar_donor_acceptor_chr22_5vars_mutmap.hdf5"
Now we are ready to calculate the mutation map data:
! kipoi veff create_mutation_map $model_name --dataloader_args $dataloader_arguments_str \
--scores logit --output $output_file --regions_file $query_vcf
The output of that was a hdf5 file that can either be loaded by the python API or by the CLI command plot_mutation_map as presented here:
plot_file = "example_data/clinvar_donor_acceptor_chr22_5vars_mmPlot.png"
region_start, region_end = var_pos -40, var_pos+40
! kipoi veff plot_mutation_map --input_file $output_file \
--output $plot_file --input_entry 3 --model_seq_input seq \
--scoring_key logit --model_output "SK-N-SH_RA_CTCF_None_385" \
--limit_region_genomic $region_start $region_end \
--rc_plot
[33mWARNING[0m [44m[kipoi.__main__][0m `kipoi postproc` has been deprecated. Please use kipoi <plugin> ...:
# - plugin commands:
veff Variant effect prediction
interpret Model interpretation using feature importance scores like ISM, grad*input or DeepLIFT.
[0m
And this is the result:
from IPython.display import Image
Image(filename=plot_file)
